Deep MNIST for Beginners コード解説
学生時代は機械学習ツールがそれほど整備されておらず自力で実装することも多かったです。今はAIブームで手軽に試せるフレームワークやクラウドサービスが整ってて楽ですね。
久々に機械学習の進歩を追いかけるべく、まずはTensorFlowを試してみよう。
TensorFlow:Deep Learning MNIST手書き文字認識
https://www.tensorflow.org/get_started/
概要
MNIST手書き文字
対象となるMNIST手書き文字データは0〜9の10種類の文字である。ビギナー編ではまず古典的な単純パーセプトロンを用いた多クラス分類問題としてこれを解く。つまり入力された28x28の画像データが0〜9のどの文字かに分類する。
ニューラルネットワーク設計
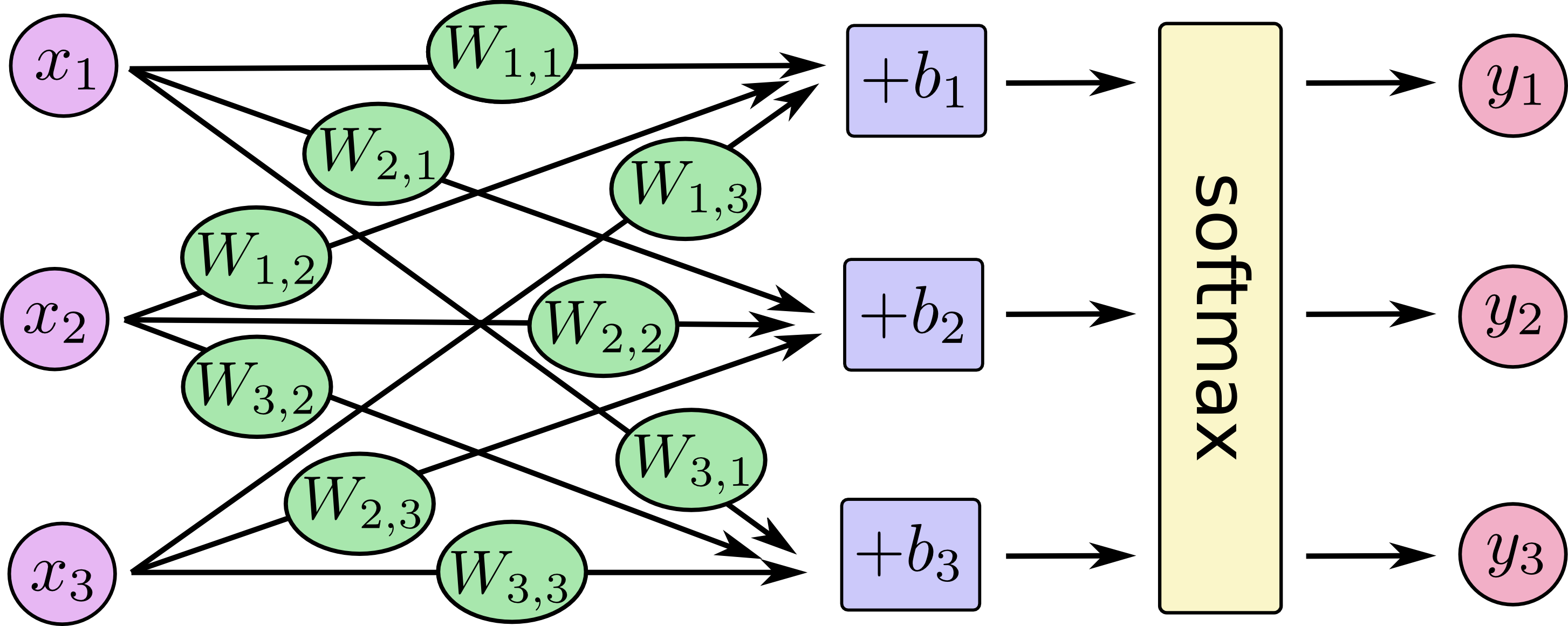
画像データ(28x28)の画素を一列に並べると784次元のベクトルとなる。が各画素に相当し、
が認識される数字の確率となる。図では簡略化のため、
の要素が3つの場合を描いている。
演算方法は単純で、各画素の値に重みを掛けてバイアス
を足している。本家の解説から少し変えて、横ベクトルと行列で表してみる。
今回は出力を確率にするため活性化関数としてsoftmax関数を利用する。softmax関数は出力を指数関数で正の値にし、総和が1になるように正規化している。
学習
このニューラルネットワークでの未知なパラメータは重みとバイアス
である。学習とは入力と対応する正解データを与えて未知なパラメータを推定することを指す。正解データを与えて推定することを特に、教師あり学習とも呼ぶ。さて、パラメータを推定するには基準が必要となる。そこで正解と出力の誤差関数(損失関数とも呼ぶ)を定義し、これを最小化するパラメータを得ることにする。出力は確率なので確率分布の類似度を測るクロスエントロピーを誤差関数として利用できそうである。
正解ラベル、出力
として誤差関数
をクロスエントロピーで定義する。誤差関数
を最小にする最適なパラメータを勾配法で解いて得ればよい。
合成関数の微分を利用して誤差関数を重み
、バイアス
について偏微分してみる。
は式(4)から得られる。
は式(3)から積の導関数の公式を利用して得られる。
これらは自明である。
は整理すると簡単になる。
ここまでの式により、最急降下法の更新式を得る。収束係数は(0.0〜1.0)の値を設定する。
コード解説
コード全容
処理は①〜⑩の順に実行される。
# Copyright 2015 The TensorFlow Authors. All Rights Reserved. # # Licensed under the Apache License, Version 2.0 (the "License"); # you may not use this file except in compliance with the License. # You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # ============================================================================== """A very simple MNIST classifier. See extensive documentation at https://www.tensorflow.org/get_started/mnist/beginners """ # ① from __future__ import absolute_import from __future__ import division from __future__ import print_function import argparse import sys from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf FLAGS = None def main(_): # ④Import data mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True) # ⑤Create the model x = tf.placeholder(tf.float32, [None, 784]) W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.matmul(x, W) + b # ⑥ y_ = tf.placeholder(tf.float32, [None, 10]) # The raw formulation of cross-entropy, # # tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.nn.softmax(y)), # reduction_indices=[1])) # # can be numerically unstable. # # So here we use tf.nn.softmax_cross_entropy_with_logits on the raw # outputs of 'y', and then average across the batch. # ⑦Define loss and optimizer cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) # ⑧ sess = tf.InteractiveSession() tf.global_variables_initializer().run() # ⑨Train for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys}) # ⑩Test trained model correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels})) if __name__ == '__main__': # ② parser = argparse.ArgumentParser() parser.add_argument('--data_dir', type=str, default='/tmp/tensorflow/mnist/input_data', help='Directory for storing input data') FLAGS, unparsed = parser.parse_known_args() # ③ tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
ライブラリインポート
# ① from __future__ import absolute_import from __future__ import division from __future__ import print_function import argparse import sys from tensorflow.examples.tutorials.mnist import input_data import tensorflow as tf FLAGS = None
from __future__はpython3の機能のインポート。あとは必要なライブラリとtensorflowのライブラリを読み込んでいる。FLAGSはパースした引数の格納に使われる。
引数のパース
if __name__ == '__main__': # ② parser = argparse.ArgumentParser() parser.add_argument('--data_dir', type=str, default='/tmp/tensorflow/mnist/input_data', help='Directory for storing input data') FLAGS, unparsed = parser.parse_known_args()
mnistのテストデータの一時保存先ディレクトリを引数で指定でき、特に指定がなければ'/tmp/tensorflow/mnist/input_data'が使用されることになる。結果はグローバル変数のFLAGSに格納される。
tensorflowアプリケーションの実行
# ③ tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
tf.app.runは残りの引数をパースして渡したメソッドを実行してくれるヘルパー関数である。なので、直接mainメソッドを呼び出しても変わらない。なお、パースした引数は以下のようにアクセスできる。
from tensorflow.python.platform import flags f = flags.FLAGS f.key # keyはパースされた引数名
mnistデータ読み込み
def main(_): # ④Import data mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
mnistのデータをダウンロードして読み込んでくれる。もちろん、本来なら自分でデータセットを用意して読み込むことになる。
モデルの作成
# ⑤Create the model x = tf.placeholder(tf.float32, [None, 784]) W = tf.Variable(tf.zeros([784, 10])) b = tf.Variable(tf.zeros([10])) y = tf.matmul(x, W) + b
ここでもう一度、式を見てみよう。式の計算通りであることがわかる。
tf.placeholderは、学習/識別計算時に与えられることを宣言している。第二引数[None, 784]は二階テンソルで、1軸目の次元数が可変、2軸目が784次元であることを示す(つまり、N×784の行列)。1軸目は入力画像数なので、任意の数の画像を一度に学習/識別が可能となる。
ところで、tf.matmul(x, W)の計算結果はN×10のテンソルだが、バイアスベクトルは階数が異なるため足せないように見える。これはブロードキャストという仕組みにより、バイアスベクトル
はN×10のテンソルに自動拡張され計算できるようにしてくれる(各行は元の
のコピー)。詳細は他所に譲る。
トレーニング用の正解ラベル
# ⑥ y_ = tf.placeholder(tf.float32, [None, 10])
教師あり学習として解くため、正解ラベルを設定するプレースホルダを宣言している。
損失関数とオプティマイザ
# The raw formulation of cross-entropy, # # tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(tf.nn.softmax(y)), # reduction_indices=[1])) # # can be numerically unstable. # # So here we use tf.nn.softmax_cross_entropy_with_logits on the raw # outputs of 'y', and then average across the batch. # ⑦Define loss and optimizer cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)) train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
各入力画像のクロスエントロピーの平均値を最小化するため、これを最急降下法で解く計算グラフをtrain_stepとして定義している。クロスエントロピーを理論どおりに実装すると指数を扱う関係で場合によってはオーバーフローを起こすため、TensorFlowで用意されているtf.nn.softmax_cross_entropy_with_logits()を利用する。
セッションの生成と初期化
# ⑧
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
TensorFlowの実際の計算は、C++で作られたバックエンドに依存している(バックエンドからCPU/GPUがゴリゴリ使用される)。Python上ではテンソルの計算グラフを定義し、セッションと呼ばれるバックエンドとのコネクションを通じて計算を実行していることになる。なぜこのような仕組みになっているかというと、途中経過を含む計算結果を毎回Pythonの変数にバインドするのはオーバーヘッドが大きすぎるため、計算グラフをバックエンド内に閉じて実行しているのである。
InteractiveSessionはその名の通りインタラクティブなので、セッション生成前に定義した計算グラフだけでなく、生成後に追加で計算グラフを定義・実行ができる。global_variables_initializerは、それまでに定義した変数、今回だとW,bを初期化している。
学習
# ⑨Train for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
学習では、sess.run()で定義した計算グラフtrain_stepを実行している。train_stepの計算グラフを辿ると、2つのプレースホルダxとy_があったことを思い出してほしい。プレースホルダは実行時に値を与えなければならない。そこで引数feed_dictでこれらを与えている。
学習においてトレーニングデータの与え方もいくつかあるが、今回はミニバッチを用いている。ミニバッチとはトレーニングデータから任意の数のデータをランダムに選択・学習を繰り返す手法である。ここでは、トレーニングデータから100個ランダムに選択して学習する処理を1000回繰り返している。
学習結果の認識精度テスト
# ⑩Test trained model correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1)) accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
学習が完了したら認識精度テストを実行する。精度は正解数の平均値として定義している。tf.argmax(y, 1)は、テンソルyの各行の最大値のインデックスを返す。正解y_と予測yが一致するなら同じインデックスを指すはずなので、tf.equalはtrueかfalseを返す。tf.reduce_mean(tf.cast(correct_prediction, tf.float32))でboolをfloat32に変換(true -> 1.0, false -> 0.0)し、平均値を算出している。
なおsoftmax関数は単調増加なので、ここでは予測yにsoftmax関数を適用しなくても問題ない。具体的な確率を表示させたい場合は、tf.nn.softmax(y)を出力する。
【書評】誰が音楽をタダにした? 巨大産業をぶっ潰した男たち
")
誰が音楽をタダにした? 巨大産業をぶっ潰した男たち【無料拡大お試し版】 (早川書房)
- 作者: スティーヴンウィット
- 出版社/メーカー: 早川書房
- 発売日: 2016/09/07
- メディア: Kindle版
- この商品を含むブログを見る
久々に熱中して一気に読み切った本。テクノロジーが時代を変えた出来事の象徴と言ってもいいのではないだろうか。ファイル交換ソフト狂乱時代をよく知る人はハマると思います。10代や20代前半はあまりピンとこないかもしれませんね。
物語は「MP3を作った研究者」、「大手レーベルを渡り歩きながら次々とヒットを生み出したエグゼクティブ」、「誰にも知られずアメリカの音楽を流出し続けたCD工場労働者」の3人を軸に展開される。
とあるドイツの研究者が産んだ画期的なテクノロジー、それがオーディオ圧縮技術である。この技術の画期的なところは、人の聴覚特性を利用したことにある。音というのは様々な周波数で構成されるが、人の聴覚はその全てを聞き取って区別しているわけではない。聞き取れる周波数の下限・上限があるだけでなく、脳は人の声など意味論的に重要な音に注目する特性がある。これを逆手にとって人が認知しない音をオーディオデータから除外すれば、データ量を削減、すなわち圧縮することができる。しかし研究者は技術力は素晴らしくてもビジネスマンとしては未熟であったため、MPEG標準化において大手メーカーの戦略により、技術的に不利な譲歩をしなければならなかった。結果、MP3には彼の技術が中途半端な形で採用されることになる(のちにAACで彼の技術が真価を発揮することになる)。MPEG標準で採用されたものの、その後もビジネスとしては芳しくなかったため、普及のためにMP3エンコーダをインターネットで公開したのだった。これに目をつけたのがネットのアングラたちで、CDからMP3にエンコードすることで当時は低速だったネット回線でも送受信することができ、海賊版音楽ファイルの共有が劇的に広がっていったのだった。海賊版音楽ファイルの流出に大きな役割を果たすことになるのが、音楽CD工場に勤務する一人の労働者なのだが、気になる方はぜひ本を読んで欲しい。
ところで私が初めてMP3を知ったのはまだ中学生だった頃、父が嬉しそうにMP3エンコーダを買ってきた時だった。父はほとんど音楽を聞かないのに「これからはMP3の時代だ」とか言ってて、PCに持っているCDをMP3化して入れていたのだった。私は「いちいち聞くのにPC立ち上げるとかめんどくさい」と突っ込んでいたが、ちょうど高校生に上がるときに雑誌でSDカード式のMP3プレーヤを見つけて、これだ!と思ったものの、SDカードの容量はまだ最大でも64MBでせいぜいアルバム一枚入れるが限度だった上に、SDカード自体も数千円と高価で諦めたのだった。少しするとiPodが登場したがやはり高価で諦めてしまった(友人が持ってて憧れたものだ)。折しもWinMXなどのファイル共有ソフト全盛期。しかしその裏で、この本の物語が進行していたと思うと、なんとも感慨深いものがある。
Line Bot の Play framework テンプレート in Scala
macOS Sierra - Samba安定化
2017/11/17 追記
アップルが公式にSMBのパフォーマンスアップについてアドバイスしているのを見つけた。
パケット署名を無効化しSMB3にするとファインダーでNASを参照しても遅くなったり固まったりすることがなくなったので、このまま様子見してみる。セキュリティ的にはよろしくないようだが、ファイル共有はプライベートネットワークでしか使ってないので問題ないだろう。
support.apple.com
[本文]
去年、macOSでのSamba安定化について書いたが、Sierraになって方法が変わったのでメモ。
SMB1にする
こうすればいい。
/etc/nsmb.conf
[default] protocol_vers_map=1
エンジニアの価値
私も普段はSIerをdisってばかりですが、じゃあWeb系が至高とも言い切れないモヤモヤを抱えて生きてます。
イケてる環境のWEB系の労働生産性がイケてないSIerのたった三割しかない件 - プロマネブログ
資本主義における自由市場経済ではお金がものをいうわけで、すなわちお金の生産性として語るほうが指標としてはわかりやすい。
金で測るエンジニアの生産性
経営者の力量や営業の成果との比は単純に比較しようもないので、ポジションによる影響を無視すると、エンジニアの生産性は以下で示される。
エンジニアの生産性をあげるには、高付加価値のプロダクトを作って売上立てるか、プロダクトの生産効率を上げて開発人数減らすしかない。エンジニアの考える生産性ってコード書いた量とかスピードに注目されがちですが、それにも当然限界があって、いかに付加価値を作るかを考えねばならない。
どこかで聞いた文句、「売上はすべてを癒やす」とはエンジニアの生産性にも寄与しているわけです。利益あってのエンジニア。
エンジニアの幸せ
エンジニアは技術が好きだからやってるわけです。お金だけでは満たされない。
クールなプロダクトを作りたい。
最先端の技術を使いこなしたい。
最高の開発環境でストレスフリーにコーディングしたい。
オシャレなオフィスで、そしてたまにスタバでドヤりながら仕事したい。
やることやってれば、出社時間・勤務時間なんて自由でいいと思う。別にイヤホンで音楽聴きながらやったって誰かが迷惑するわけでもないし。私も激しく共感します。
エンジニアの給与
SIerの世界なんて数億程度のプロジェクトなんてざらにあるし、そんなの小さい部類です。SIerの顧客って大きなお金を動かせる人が多いし、特注の作り込みが必要なら値段ふっかけるもんです。結果として売上・利益も大きく、ひいては給与も高いと期待できる。
Web系で働いてたとき、「俺のほうができるのになんであいつと給料変わんないのか」とか愚痴ってる人いたけど、会社内の相対的な差を気にしてもしょうがないと思う。その人は転職して給与あがって、めでたしめでたし。結局、お金は気になるわけですね。
給料あげたい? Welcome to SIer as Project Manager!!
(プロマネは責任も大きいわけで、でかいプロジェクトでこけると何人か首飛びますけど。)
エンジニアの価値をあげるにはどうするか
Web系の人たちは技術力向上において、すごく努力してると思います。SIerで見た「俺、人集めるしかできない」とか言って丸投げしてた方より、よっぽどWeb系で頑張ってる人を尊敬してます。
でも、技術だけでは足りない。どうやって価値を上げるか。
私は、桁違いにスケールの大きな夢を真面目に追う人を、エンジニアリングで応援するのがいいと思ってます。例えば、火星に行くとか言ってるクレイジーな天才など。
その夢が叶ったとき、巨大な利益と技術力(エンジニアリングとしての生産性)が相まって、エンジニアの価値が真に高まるでしょう。
あってもなくてもいいようなサービスとか、浮き沈みの激しいゲームとか作ってても、いつまでもエンジニアの価値は上がらないんじゃないだろうか。
Haskell道 その5
前回はファンクターでした。
今回はアプリカティブファンクターです。
アプリカティブファンクターとは?
ファンクターは文脈を持った値を入れる箱でした。値は整数、浮動小数点数、文字列などです。ところでHaskellは関数がファーストクラスでした。つまり関数を値のように扱えるということです。となると、ファンクターに関数を入れてもいいのでは? 答えはYes。ファンクターに関数も入れられるようになったのがアプリカティブファンクターです。
言い換えると、アプリカティブファンクターは文脈を持った関数も入れられる箱です。なお、アプリカティブファンクターでは長くて呼びづらいので単にアプリカティブと呼んだりします。
アプリカティブに値を適用
箱の中に関数があるのですから、関数に値を適用したいですよね。それが <*> です。
試しにMaybeのアプリカティブに値を適用してみましょう。
Prelude> let a = Just (+2) Prelude> a <*> Just 3 Just 5
「2を足すかもしれない」ものに対して「3かもしれない」ものを適用すれば、「5かもしれない」ものになりました。ここでもMaybeの文脈が維持されていますね。
pure と <*>
ここでアプリカティブの定義を見てみます。
class (Functor f) => Applicative f where pure :: a -> f a (<*>) :: f (a -> b) -> f a -> f b
f (a -> b) -> f a という定義からアプリカティブに値を適用するには、同じ文脈に入れたファンクター値で与えなければなりません。上述のMaybeの例だと、a に適用するのに Just 3 でわざわざファンクター値にしていました。ここで a はアプリカティブであれば何でもいいような抽象的なコードの場合、具体的な型がわかりません。そこで pure の登場です。pure :: a -> f a の定義の通り、与えられた値を文脈にいれて返すだけです。
Maybeの例をpure で書きなおしてみましょう。
Prelude> let a = Just (+2) Prelude> a <*> pure 3 Just 5
pureの活用方法は他にもあります。例えばアプリカティブではない関数にファンクター値を適用する場合です。まずは fmap でやってみます。
Prelude> fmap (+) (Just 3) <*> Just 4 Just 7
それならば、最初から(+)をアプリカティブにして <*> を連鎖させて部分適用していっても良さそうです。
Prelude> pure (+) <*> Just 3 <*> Just 4 Just 7
これでも十分そうですが便利な中置演算子 <$> を利用することもできます。
Prelude> (+) <$> Just 3 <*> Just 4 Just 7
<$> の実体は fmap のエイリアスなので、ファンクターがアプリカティブを実装していなくても使うことはできます。
(<$>) :: (Functor f) => (a -> b) -> f a -> f b f <$> x = fmap f x Prelude> (+3) <$> Just 3 Just 6
アプリカティブ則
第一法則「idのアプリカティブで写してもファンクター値は同じである」
pure id <*> v = v
第二法則「アプリカティブの連鎖でファンクター値を写したものと、アプリカティブで関数合成してからファンクター値を写したものは同じである」
pure (.) <*> u <*> v <*> w = u <*> (v <*> w)
第三法則「文脈に入れてから関数に適用したものと、関数に適用してから文脈に入れたものは同じである」
pure f <*> pure x = pure (f x)
第四法則「アプリカティブでファンクター値を写したものと、ファンクター値を$演算子で関数化してアプリカティブで写してものは同じである」
u <*> pure y = pure ($ y) <*> u
まとめると、ファンクター則と同様に与えられた関数や値を無視したり、関数適用以外の余計なことはしないということですね。箱はあくまで箱であり、入れ物にすぎないということです。
補足:
$演算子は優先度の低い演算子であるため引数を右結合させたい場合(かっこを減らしたい場合)に有用という記述をわりと見かけますが、それだけでは少々説明不足です。
($) :: (a -> b) -> a -> b f $ x = f x
$は関数本体と引数を受け取り引数を関数本体に適用する優先度の低い演算子です。これは関数適用を右結合させる以外のもう1つの活用方法として、関数が引数を待つのではなく、引数が関数を待つ関数を作ることができます。
Prelude> let f = \x -> x + 1 Prelude> :info f f :: Num a => a -> a Prelude> let p = ($ 1) Prelude> :info p p :: Num a => (a -> b) -> b Prelude> p f 2
$は演算子なため中置記法(f $ x)が可能でした。なので($ 1)とすれば右引数を部分適用した関数が作れます。なお、すごいHaskellたのしく学ぼう!の5.6章にも詳しい解説があります。
Haskell道 その4
前回からかなり空いてますがHaskellの勉強はゆったりながら続けてますよ。
途中の章はいろいろ飛ばしてファンクターに行きましょう。
ファンクターとは?
ファンクターは文脈を持った箱です。箱の中にある値に文脈を持たせるともいえます。箱なので値を取り出して、加工して、また戻すこともできます。
ファンクターといえば、Maybe型が有名です。
Maybeの定義はこちら。
data Maybe a = Just a | Nothing
ここでの a は箱に入れる値の型です。Java的にはジェネリクス。
Maybe型とは、値に不確実性の文脈を与えます。日本語的には「もしかすると〜かもしれない(失敗していなければ)」という意味です。
ファンクター値に関数を適用
ファンクターの箱の中にある値をファンクター値と呼んだりします。そしてファンクター値に関数に適用するのが fmap です。関数に適用させて得られた値はそのままファンクターに包まれたままです。イメージとしては、箱の中に入れたまま値を関数に適用させる感じです。
試しにMaybeのファンクター値に対して3を掛けてみます。
Prelude> let a = Just 2 Prelude> a Just 2 Prelude> fmap (\x -> x * 3) a Just 6
「2かもしれない」ものに対して3を掛ければ、「6かもしれない」ものになりました。ここで重要なのは文脈が維持されることにあります。
ファンクター則
第一法則「idで写してもファンクター値は同じである」
id は 与えられた引数をそのまま返す関数です。Maybeで示すと以下が成り立つ。
fmap id (Just 3) == id (Just 3)
第二法則「gの次にfでファンクター値を写したものと、合成関数f・gでファンクター値を写したものは同じである」
Maybeで示すと以下が成り立つ。
fmap f $ fmap g (Just 3) == fmap (f . g) (Just 3)
まとめると「箱から値を取り出して、与えられた関数を適用して、また戻す」という動作のみが fmap で実装されていればいいことになる。
与えられた関数を無視したり、関数適用以外の余計なことはしないということですね。